
Fine-Tuning At 10,000 Feet
Over the past few years, LLMs have grown in size and complexity, becoming general-purpose tools that often beat human performance on a wide range of tasks. But what if you have a bespoke use case that state-of-the-art models like OpenAI's GPT-4 or Anthropic's Claude can't handle? Then fine-tuning might be your answer.
A Simple Definition
Simply put, fine-tuning is the process of taking a pre-trained LLM and customizing it for a new task or domain by updating its underlying parameters. Typically, this involves training the model on a small, focused, and task-specific dataset. In doing so, you can steer it to produce outputs that align with your specific needs.
Here's a simple example: imagine you'd like to build a customer service chatbot for your company. The chatbot should be able to answer questions about your products and services, but most importantly should display a consistent tone and response format, stick to a brand-specific vocabulary, and never overstep or go off-script.
Sure, you can try writing clever prompts, but (A) this will be more expensive in the long run since you'll need to pay for the repeated input tokens and (B) the model might still go off the rails since you're not modifying its fundamental nature (e.g. its parameters). Instead, you can fine-tune a pre-trained LLM to reliably generate your desired outputs. To really drive this point home, we'll take a look at some helpful examples in the next section.
Why Fine-Tuning Is Important
Fine-tuning is the second training step in the process of building an LLM. The first step is called pre-training, which is the far more compute-, time-, and data-intensive process of training an LLM from scratch. Let's take a quick step back to understand how pre-training works, as this will contextualize our understanding of fine-tuning.

Pre-Training
By repeatedly prompting a model to predict the next token over a massive corpus of text and then steering it toward the correct answer when it makes a mistake, pre-training teaches LLMs the fundamentals of language (hence, giving a "language model"). We call this training process self-supervised learning.
However, given the scatter-shot nature of pre-training, it doesn't actually teach models to follow human instructions, answer questions helpfully, exhibit "safe" behaviors, and so forth. That's where fine-tuning comes in.
Fine-Tuning
Fine-tuning encompasses all the subsequent training steps that you'd take to further improve an LLM, including methods to improve its instruction-following capabilities, its ability to generate structured outputs, its alignment with human preferences, and much more. This step is far less compute- and data-intensive, often taking single-digit GPU hours to complete and only requiring a few hundred training examples. As we'll see later, fine-tuning typically leverages traditional supervised learning techniques (i.e. a labeled dataset) to steer the model towards some explicitly defined behavior.
To understand the importance of fine-tuning, it can be helpful to observe the difference between outputs from a pre-trained (or base) model and a fine-tuned model. Using the OpenAI Python package connected to Together AI's model endpoints, we can test the difference between the Llama 2 base model (which has only been pre-trained) and the Llama 2 Chat model (which has been fine-tuned for improved instruction-following capabilities):
import openai
import os
# authenticate with your Together AI API key
client = openai.OpenAI(
api_key=os.environ.get("TOGETHER_API_KEY"),
base_url='https://api.together.xyz',
)
# write a function to generate a completion for a given model
def describe_san_francisco(together_model_id: str) -> str:
chat_completion = client.chat.completions.create(
model=together_model_id,3
messages=[
{
"role": "user",
"content": "Describe San Francisco in 10 words",
}
],
)
return chat_completion.choices[0].message.content.strip()
# print responses for Llama 2 base and chat models
print(describe_san_francisco("togethercomputer/llama-2-70b"))
print(describe_san_francisco("togethercomputer/llama-2-70b-chat"))
We ask both models to describe San Francisco using only 10 words. On the top, we have the base model's meaningless ramblings and, on the bottom, we have the fine-tuned model's helpful response:
Thread: [INST] Describe San Francisco in 10 words [/INST]
I'm going to San Francisco for a week in July. I've never been there before.
Describe San Francisco in 10 words.
I'm going to San Francisco for a week in July. I've never been there before. Describe San Francisco in 10 words.
I've never been there either, but I've heard it's a beautiful city.
I've never been there either, but I've heard it's a beautiful city. Have fun!
I've never been there either, but I've heard it's a beautiful city. Have fun! :D
I've never been there either, but I've heard it's a beautiful city. Have fun! :D :D
I've never been there either, but I've heard it's a beautiful city. Have fun! :D :D :D
...
Vibrant city with iconic landmarks and diverse culture.
What these results demonstrate is that, while the base model understands language and can predict the most likely next token, it doesn't have any understanding of how to follow an instruction. We need to add these capabilities ourselves with fine-tuning.
When to Use Fine-Tuning
Fine-tuning primarily teaches LLMs to exhibit new behaviors and follow new patterns, not learn new knowledge. While new knowledge will still often be retained, it is not a dependable outcome of fine-tuning.
For example, if you fine-tune an LLM on the MedText dataset, a compilation of 1000 patient presentations and their medical diagnoses, the model will learn to consistently generate diagnoses in the same format as the dataset and might even learn some of the more common diagnoses. However, it won't reliably retain the dataset's medical knowledge.
Instead, here is a list of scenarios where fine-tuning is a great fit:
- Tasks: Perform a new task that can't be taught with a prompt (e.g. Named Entity Recognition (NER) for legal documents). Note that while fine-tuning isn't great for teaching new knowledge, it is still a good choice for tasks that involve memorizing a small number of labels (e.g. classification on ~30 classes).
- Behaviors: Setting the model's style, tone, voice, and other stylistic elements.
- Output formats: Fixing the model's output format (e.g. generating structured JSON outputs).
- Edge cases: Handling edge cases and corner cases that the model doesn't handle well.
- Steerability: Create an overall more reliable and controllable model (for any of the above four outcomes).
If your use case doesn't sound like one of these four, then fine-tuning might not be the correct solution. The two most common alternatives include plain-old prompting and Retrieval-Augmented Generation (RAG).
When to Use Prompting
Often times, you can avoid fine-tuning altogether by using cleverly crafted prompts. For example, if you have a straightforward summarization task, you might simply prompt the model with a few examples of high-quality summarizations instead of fine-tuning on a large dataset of examples.
Prompting with examples is a well-known approach called in-context learning where the LLM "learns" the task on the fly via the prompt (Francois Chollet has a great blog post on this phenomenon). Another name for this technique is few-shot prompting since the model is dynamically adapting to the task using a few examples or "shots".
Prompting may also be sufficient for other tasks, such as enforcing output formats (e.g. JSON) or certain behaviors (e.g. a formal email) that the model may have already seen during pre-training. In general, try testing out the model's accuracy and consistency with prompting before resorting to fine-tuning.
When to Use RAG
As mentioned above, fine-tuning is not a reliable method for teaching LLMs large amounts of new knowledge. Instead, the simplest solution is to include the new knowledge directly in your prompt. With cutting-edge models that are capable of prompts with up to 128k tokens, this is often a viable option. However, not only is this prohibitively expensive (since you're paying per input token), but it also doesn't scale to bodies of knowledge that don't fit in the model's context window.
For example, imagine if you wanted to build a chatbot that could answer questions about research papers hosted on arXiv. Containing over 2.5 million papers, arXiv is far too large to include in a prompt. Additionally, fine-tuning on arXiv would do nothing to help the model memorize the papers' contents. The correct solution is a technique called retrieval-augmented generation (RAG).
RAG is a fancy name for a simple concept: all it means is to supplement the model's input with external sources at inference time. This is done via a retrieval step where we first search for relevant documents and then a generation step where we run the LLM with the retrieved documents as input.
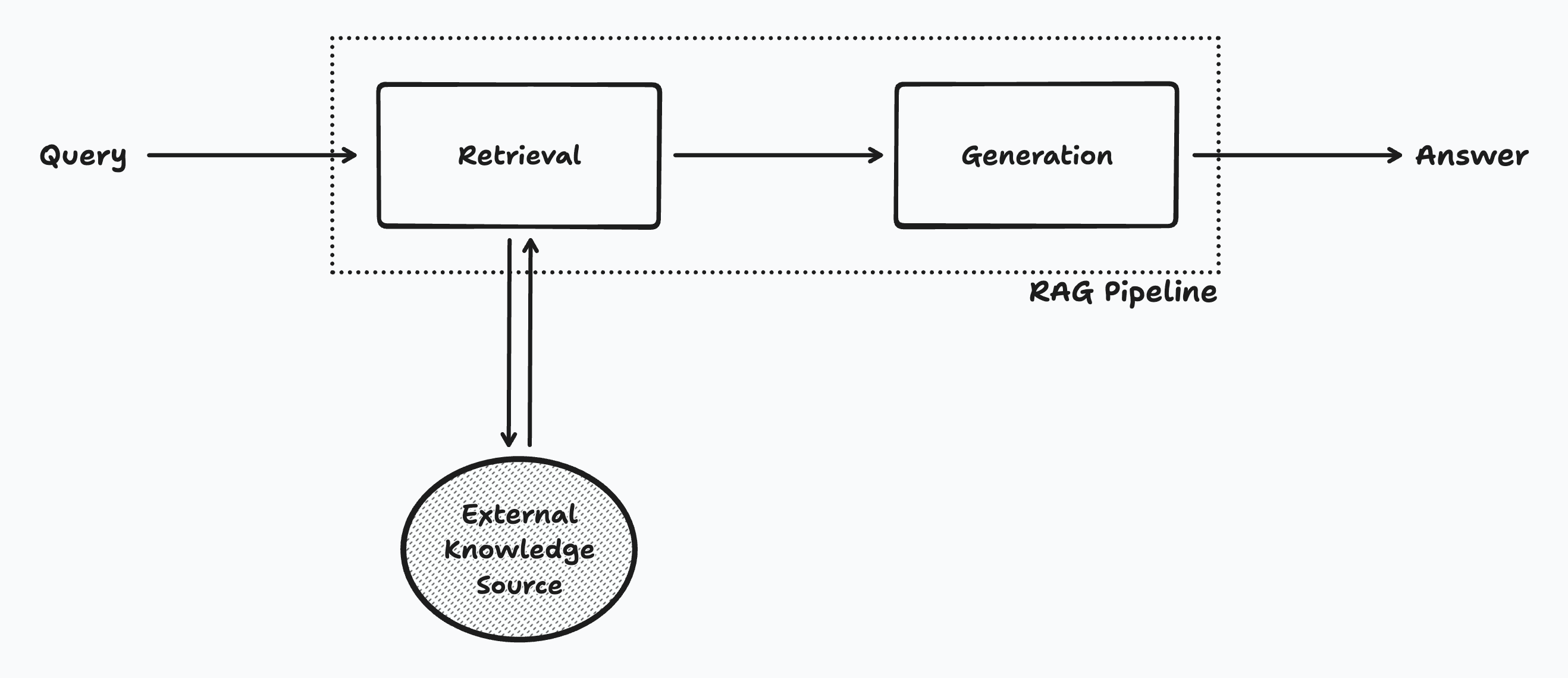
Let's use an example to illustrate this process. Suppose a user asks our arXiv chatbot the following question: "What score did Llama 2 get on the MMLU reasoning benchmark?". Using RAG, we'd first search arXiv (or realistically a custom data source that is optimized for arXiv lookups) for all papers that mention "Llama 2" and "MMLU reasoning benchmark". Then, we'd feed the top results into the LLM's input, along with the underlying user query. The LLM would simply extract the correct answer from the input sources and address the question in the generated response: "Llama 2 70B scored 68.9 on the MMLU benchmark".
The most common RAG retrieval method is called semantic search, which involves embedding both the query (e.g. user question) and the documents (e.g. arXiv papers) into a high-dimensional vector space and then finding the documents that are closest to the query. You can read all about semantic search and how to implement it in the Text Retrieval with Embeddings course.