
Fine-Tuning with the OpenAI API
Now for the fun part — actually fine-tuning our model! To do so, we will use OpenAI's fine-tuning API via their Python library, which you can install with pip:
pip install openai
Then, we can retrieve our API key from the OpenAI dashboard (stored as an environment variable called OPENAI_API_KEY below) and initialize the OpenAI client:
import openai
client = openai.Client(
api_key=os.environ['OPENAI_API_KEY']
)
Preparing the Files
We'll start by uploading both the training and validation splits to the platform. OpenAI expects the data to be formatted as JSON Lines (JSONL), which is a file format that simply places each JSON object on a new line. In our case, each line will receive a single example from our training or validation splits. Let's define a function write_jsonl below to map our data to this format:
def write_jsonl(data: list[dict], path: str):
with open(path, 'w') as file:
for example in data:
json.dump(example, file) # dump a single example to the file
file.write('\n') # add a newline character to separate examples
write_jsonl(train_data, 'train.jsonl') # creates our training JSONL
write_jsonl(validation_data, 'validation.jsonl') # creates our validation JSONL
Let's use the Python library's client.files.create method on the files we just generated to upload them to the OpenAI platform. We'll set the purpose parameter to fine-tune and then print out the uploaded file IDs and their statuses:
# upload our training JSONL to OpenAI
train_file = client.files.create(
file=open('train.jsonl', 'rb'),
purpose='fine-tune',
)
# upload our validation JSONL to OpenAI
validation_file = client.files.create(
file=open('validation.jsonl', 'rb'),
purpose='fine-tune',
)
print(train_file.id, train_file.status)
print(validation_file.id, validation_file.status)
file-lIMNKOa1YJh3ojc43zSx4nXX processed
file-l0JgYqLA06bRzYzW1ETTRnzH processed
You should now see your files in the OpenAI dashboard under "Files":
Fine-Tuning the Model
Let's fine-tune our model! We'll call OpenAI's client.fine_tuning.jobs.create method along with the training and validation file IDs, the target model ID, hyperparameters to configure training, and a suffix to customize the new model's name:
job = client.fine_tuning.jobs.create(
training_file=train_file.id,
validation_file=validation_file.id,
model="gpt-3.5-turbo",
suffix="customer-intent",
hyperparameters={
"batch_size": 'auto',
"learning_rate_multiplier": 'auto',
"n_epochs": 'auto'
}
)
At the moment, the latest and most competent model that is available for fine-tuning is GPT-3.5 Turbo, which we have selected above. Note that GPT-4 Turbo fine-tuning is currently in private preview and the legacy fine-tuning models (Davinci and Babbage) will soon be deprecated.
Additionally, while you have control over the three hyperparameters above, it is recommended to set them to auto so that OpenAI can automatically choose the best values for your task. In future training cycles, if you are unsatisfied with the training results, you can manually adjust these hyperparameters (e.g. decrease the number of epochs if you notice that the model starts overfitting).
To monitor your fine-tuning job, you can use the client.fine_tuning.jobs.list method to list out all your jobs or the client.fine_tuning.jobs.retrieve method on the job ID:
client.fine_tuning.jobs.retrieve(job.id)
SyncCursorPage[FineTuningJob](data=[FineTuningJob(id='ftjob-xNXDAta4nsZ0gS9AYKjwv1G0', created_at=1707280613, error=None, fine_tuned_model=None, finished_at=None, hyperparameters=Hyperparameters(n_epochs=3, batch_size=1, learning_rate_multiplier=2), model='gpt-3.5-turbo-0613', object='fine_tuning.job', organization_id='org-58M4E8Ww6cNRze6E0fwWSpu3', result_files=[], status='running', trained_tokens=None, training_file='file-lIMNKOa1YJh3ojc43zSx4nXX', validation_file='file-l0JgYqLA06bRzYzW1ETTRnzH')], object='list', has_more=False)
From the status field, we observe that our model is currently running. We can also see the selected hyperparameter values, the specific model ID, the number of trained tokens, and other useful information.
With around 22,000 tokens in the dataset and 3 epochs, our training job took only 40 minutes to complete! Now that the job is complete, we can retrieve the status, the ID of the fine-tuned model, and the number of trained tokens:
job = client.fine_tuning.jobs.retrieve('ftjob-xNXDAta4nsZ0gS9AYKjwv1G0')
print('status', job.status)
print('model', job.fine_tuned_model)
print('trained tokens', job.trained_tokens)
status succeeded
model ft:gpt-3.5-turbo-0613:alex-langshur:customer-intent:8pUZq5me
trained tokens 65859
Even more conveniently, you can go to the fine-tuning section of the OpenAI dashboard, select your fine-tuning job, and observe the learning curves for the training and validation splits:
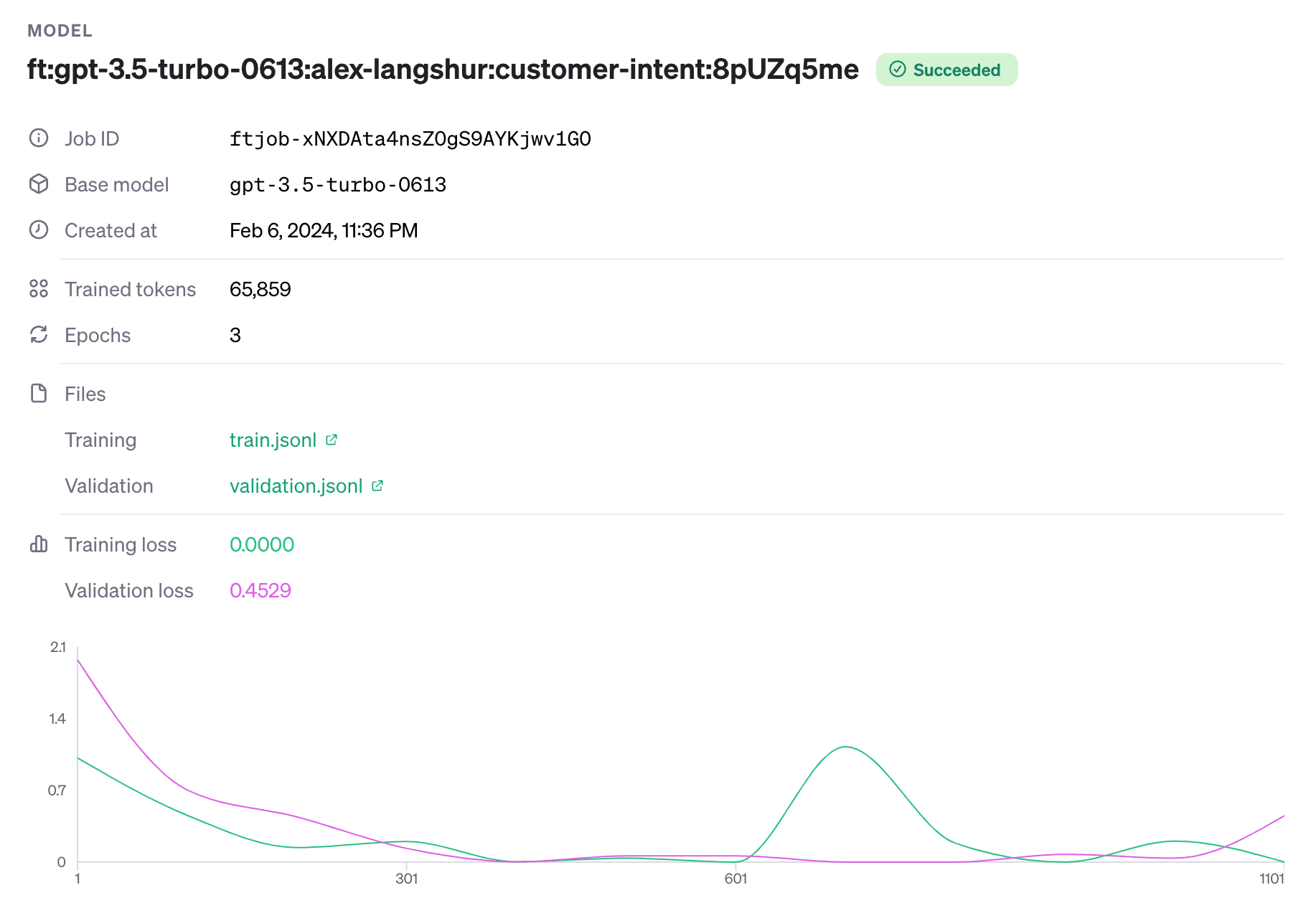
These curves show the loss of the model on both the training and validation splits after each training batch (in our case, the batch size is just a single example as shown by the output above). As we saw in the previous lesson, the loss is a measure of how well the model is performing on the task. The lower the training loss, the better the model is learning the training data. And the lower the validation loss, the better the model is generalizing to new examples.
In our case, we see that both losses decreased together and then, once the validation loss started to increase, the training job was stopped as the model was starting to overfit. If you want to learn more, here is a great guide that explains learning curves in more detail.
Using the Fine-Tuned Model
The last step is to demo our fine-tuned model! Let's use the Chat Completions API to write a function that takes our customer inquiry, passes it to the fine-tuned model with the same system prompt we used above, and then returns the model's response:
def classify_customer_intent(inquiry: str) -> dict:
completion = client.chat.completions.create(
model=job.fine_tuned_model, # the ID for our fine-tuned model
messages=[
{
"role": "system",
"content": instruction
},
{
"role": "user",
"content": inquiry
},
],
temperature=0
)
return json.loads(completion.choices[0].message.content)
The Chat Completions API's client.chat.completions.create method expects the exact same JSON chat format that we used before in fine-tuning our LLM, but this time we will exclude the assistant message (i.e. the output) so that the model generates it for us. We've also set the temperature parameter to 0, which will make the model more focused and deterministic. We then take the model's stringified JSON response and use json.loads to convert it into a Python dictionary. Let's test it out:
print(classify_customer_intent("hey i wanna to cancel my order"))
print(classify_customer_intent("Excuse me good sir! When doust thy sale end?"))
print(classify_customer_intent("hey dude, i think i got locked out of my account..."))
{'category': 'Order Management', 'sub_category': 'Cancellation'}
{'category': 'Product Information', 'sub_category': 'Promotions'}
{'category': 'Account Management', 'sub_category': 'Account Recovery'}
Wow, how about that? Everything we throw at the fine-tuned model is classified correctly. These results demonstrate several impressive outcomes:
- Since we never prompt the model with the list of categories or sub-categories, the fine-tuned model has actually memorized them all.
- The model has learned to generate flawless, artifact-free JSON outputs that we can easily load into Python dictionaries. Not bad, not bad at all.
- The model generalizes to unseen examples that are unlike anything in its training data! This is the power of fine-tuning LLMs: these models have such strong latent understandings of language that with only a little guidance, they can display amazing, unexpected behavior.
Pricing
Fine-tuning on the OpenAI platform is incredibly inexpensive for most use cases. Priced at only $0.0080 per 1k tokens of training data for GPT-3.5 Turbo, the cost of training our customer intent classification model was about half a dollar: 65859 tokens * 0.0080 $/1k tokens = $0.53. In general, the cost of fine-tuning will follow this formula:
cost per 1k tokens * number of tokens in the train file * number of epochs trained
When using our fine-tuned model for predictions, input tokens are priced at $0.0030 per 1k tokens, and output tokens are priced at $0.0060 per 1k tokens. Since the prices are subject to change, always reference the latest prices on the OpenAI pricing page.
For more information on counting tokens, limits on input tokens, and general best practices for fine-tuning, go read OpenAI's comprehensive documentation on fine-tuning!