
Applying LoRA
Enough theory, let's put LoRA to the test. In this brief example, we'll use the Hugging Face transformers Python package to load pre-trained LLMs from Hugging Face, along with Hugging Face's peft package (peft = parameter-efficient fine-tuning) to perform LoRA fine-tuning.
Loading the LLM
Hugging Face Transformers
As we've seen in other courses, Hugging Face is a community-sourced hub of hosted models, datasets, leaderboards, and educational resources for AI. It is the GitHub of the AI world. One of the biggest use cases for Hugging Face is to host open-source pre-trained LLMs, which you can easily load locally, fine-tune, and run using Hugging Face's transformers Python package. Install the package using pip:
pip install transformers
The transformers package provides a simple interface for downloading and using pre-built models hosted on Hugging Face for a variety of NLP tasks, such as classification, question answering, and text generation. Each task has its own "auto class", which is a Python class that automatically selects the correct LLM architecture and tokenizer for your intended task, retrieves the corresponding PyTorch implementation, and then populates the model with the pre-trained parameters from Hugging Face.
For example, let's say you wanted to fine-tune an LLM to perform sentiment analysis of movie reviews. To retrieve the correct model for this sequence classification task, you would use the AutoModelForSequenceClassification class:
model = AutoModelForSequenceClassification.from_pretrained("meta-llama/Llama-2-7b-hf")
isinstance(model, LlamaForSequenceClassification) # True
In the code above, the model will automatically resolve to a LlamaForSequenceClassification instance. This is Hugging Face's PyTorch implementation of Meta AI's Llama 2 model, but with a sequence classification head attached to its final layer (i.e. a linear layer that maps the model's outputs to scores for each class). The model will then download the pre-trained parameters from the meta-llama/Llama-2-7b-hf repository on Hugging Face.
LlamaForSequenceClassification is a task-specific subclass of LlamaModel, which contains the core Llama architecture. There are also LlamaForCausalLM and LlamaForQuestionAnswering, for example, which are also subclasses of the core LlamaModel implementation and are used for different tasks. You can look at all the available subclasses here.To demonstrate the flexibility of this library, you could alternatively specify lmsys/vicuna-7b-v1.5 to load the popular Vicuna fine-tune of Llama 7B, which would similarly resolve to a LlamaForSequenceClassification instance.
The Hugging Face auto classes support every major LLM architecture, many different tasks (e.g. text generation, question answering), and even multiple machine learning backends (e.g. PyTorch, TensorFlow, FLAX). You can explore all the auto classes here.
Causal LM Task
The most popular task for LLMs, and the task we'll be using, is called causal language modeling. In this task, the model is trained to autoregressively predict the next token in a sequence given all the preceding tokens (hence, "causal"). This is a fancy way to describe the behavior that we're all familiar with when using LLMs to generate text in tools like ChatGPT.
In the examples below, we'll be using Mistral 7B, the 7-billion parameter LLM from the French AI startup Mistral. In order to retrieve Hugging Face's PyTorch implementation of Mistral with the correct configuration for the causal language modeling task, we'll use the AutoModelForCausalLM auto class with the target model repository, mistralai/Mistral-7B-v0.1.
This will return a MistralForCausalLM instance, which is a subclass of the core MistralModel implementation that is adapted for iteratively generating new tokens in a causal manner and contains all 7B pre-trained parameters from the Hugging Face repository.
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1")
model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-v0.1")
In this snippet, we're also using the AutoTokenizer auto class to automatically select the correct tokenizer for the LLM. You might recall from the course on embeddings that the tokenizer is responsible for converting raw text into a format that the model can understand. Tokenizers represent the model's vocabulary and are therefore unique to each architecture.
If we then print out the total number of trainable parameters in the model, we sure enough get all 7.24 billion parameters. Full fine-tuning will be very computationally expensive!
"""
To count the number of trainable parameters, we first iterate over `model.parameters()` which is a PyTorch model-level method that returns an iterator of all the parameter matrices in the model. We can then limit this to only the trainable ones with `p.requires_grad` and finally sum the number of elements in each matrix with `p.numel()`.
"""
def count_trainable_params(model) -> int:
return sum(
p.numel()
for p in model.parameters()
if p.requires_grad
)
print(count_trainable_params(model))
7241732096
Attaching LoRA
Let's try to fix this trainable parameter count by attaching LoRA to the model. To do so, we will use the peft library, which you can install with pip install peft. The peft library was created by Hugging Face and, as such, is closely integrated with transformers. The library provides a simple interface for attaching LoRA to any PyTorch model.
To get started, all we need to do is generate a LoraConfig, which describes our LoRA fine-tuning setup, and convert our existing model to use LoRA with get_peft_model:
from peft import LoraConfig, get_peft_model
config = LoraConfig(
r=8,
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
"lm_head",
],
task_type="CAUSAL_LM", # our task type
lora_dropout=0.05,
lora_alpha=16,
bias="none"
)
lora_model = get_peft_model(model, config)
When we call get_peft_model, peft will take the existing PyTorch model, identify all the named layers that we specified in target_modules (more on that in a second), and replace their trainable parameter matrices with two smaller LoRA matrices using the config options.
The most important config option in the LoraConfig is r — this is the dimension of the and matrices as we saw before. It is most common for r to be a power of 2 in the range of 8 to 128, but is possible to see values of r as small as 2. In our case, we've chosen r=8 which would reduce a weight matrix with dimensions from 1 million parameters to only 16,000 (a 98.4% reduction)!
The target_modules option is a list of all the model's layers ("modules" in PyTorch speak) that we want to convert to LoRA. While the specifics of these modules are out of scope, in general, we should apply LoRA to every single linear layer, which is what we've done here. If you'd like to apply LoRA to a model that has a different architecture, it's helpful to print out the model layers with print(model) and then select the names of layers that you want to convert (hint: they will often be labeled with Linear or Linear4bit).
The remaining options in LoraConfig are less important but are still worth covering:
task_typeis simply the type of task that the model is configured for. In our case, we're using "CAUSAL_LM" for causal language modeling as we saw earlier.lora_dropoutis the dropout rate that LoRA will apply to parameters in the and matrices. This should remain low, around 0.0 to 0.05.lora_alphais a scaling factor that indicates how much the LoRA parameters should outweigh the existing parameters. This should stay around 16 according to the paper.biasis a flag that indicates whether or not to apply LoRA to the bias parameters in the model. This is typically set to "none".
Tuning LoRA
The paper showed that LoRA performs better with a lower r value over more layers than a higher r value over fewer layers. Therefore, a great starting point is a small r value applied to as many linear layers as possible. Even LoRA ranks as small as 2 can be effective. So start with a small r value such that you can quickly fine-tune the model with fewer trainable parameters and then gradually increase r until model performance (on your fine-tuning test set) asymptotes or you reach your desired point on the trade-off curve.
If you'd like to go deeper, there are many other config options that you can experiment with in the docs. Additionally, Sebastian Raschka has a great article on practical tips for fine-tuning LLMs with LoRA that I recommend skimming when you eventually put pen to paper.
LoRA Benefits
Now, the moment of truth. Let's print out the number of trainable parameters in the LoRA model using the same count_trainable_params routine that we defined earlier:
print(count_trainable_params(lora_model))
21260288
We've gone from 7.24 billion parameters to 21.3 million parameters! This is a 99.7% reduction in the number of trainable parameters. The most obvious benefit of this reduction is the lower computational cost of fine-tuning. We now only need to update a small fraction of the parameters at the end of each training step.
One final, less obvious benefit of LoRA is the lowered storage overhead for the model's fine-tuned parameters. We've shrunk the fine-tune-specific parameters from 29GB to 85MB. This means that we can easily store the base model once and then keep many different fine-tunes on disk. This is demonstrated in the diagram below where we have a single base model and four sets of parameters, each representing a different fine-tune:
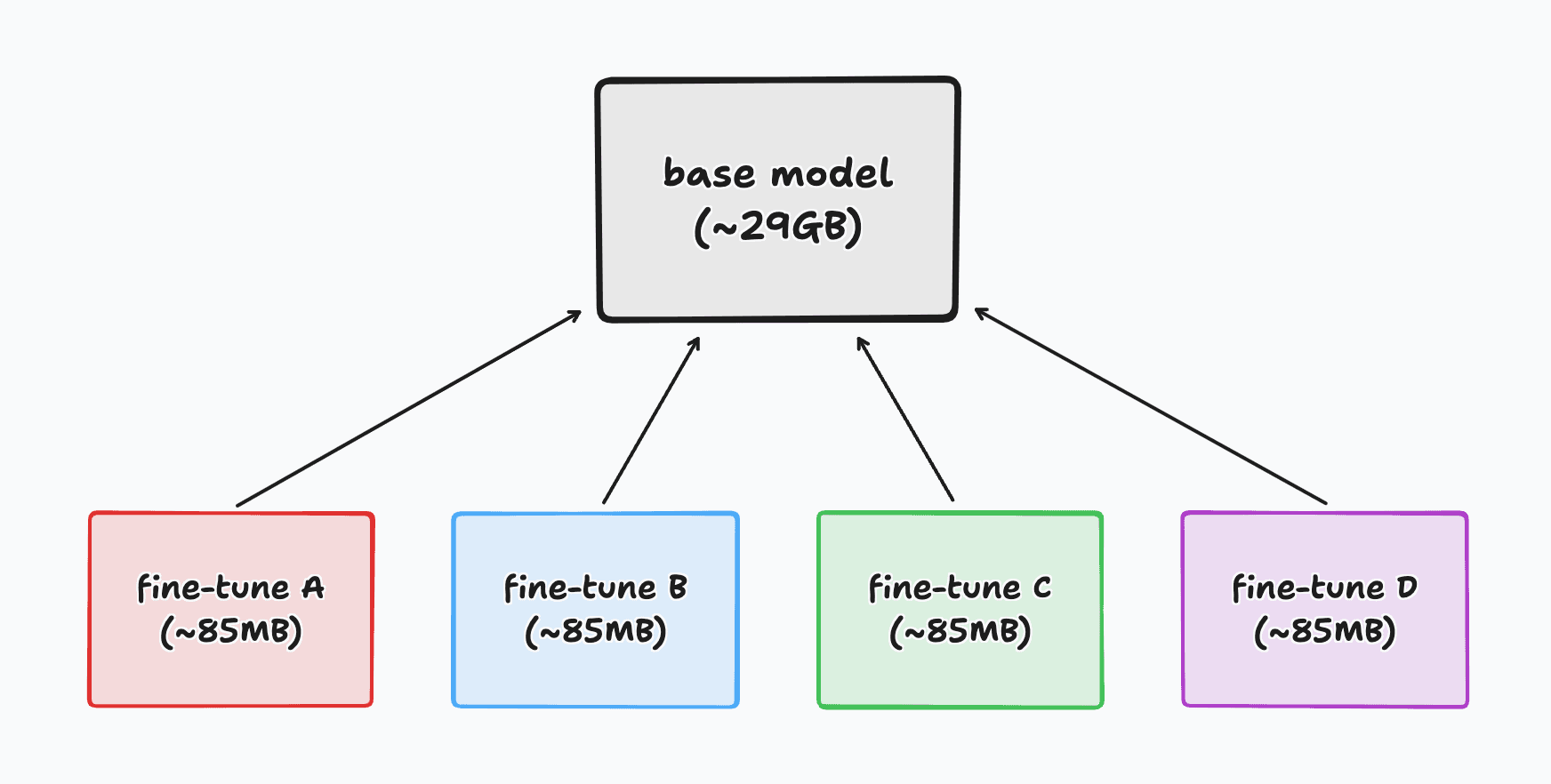
When we then need to use a specific fine-tune, we can quickly merge its 21.3 million parameters with the base model and load the merged model into GPU memory. Not only is this a huge win for open-source (i.e. easier for people to share their fine-tunes), but it also enables new business models like fine-tuning LLMs on the edge and having personalized fine-tunes for each user.
That's it for LoRA. Stay tuned for the next couple of lessons, where we'll learn about using quantization to massively reduce the memory footprint of LLMs and then put it all together to fine-tune our very own LLMs.