
Assembling BERT
Now that we understand how BERT works and why it's such a big deal, let's learn how to implement it! To do so, we'll use the Hugging Face transformers library, which provides a convenient Python interface for downloading and running transformer models that are publicly hosted on Hugging Face.
The library provides a diverse selection of ready-to-use models such as BERT that you can download locally and use for a wide range of NLP tasks. It is compatible with PyTorch and TensorFlow, the two leading deep learning frameworks, enabling easy integration of models. For our purposes, we'll use BERT's implementation in PyTorch.
Getting Started
To get started, in your Python virtual environment, you'll need to install the transformers library, along with PyTorch. We'll also use NumPy, a popular linear algebra library, for storing and interacting with our embedding vectors.
pip install transformers torch numpy
The first and simplest step is to import and build our BERT tokenizer and model. The transformers library provides us with PyTorch implementations of the two main components that we'll use for generating BERT text embeddings: BertTokenizer and BertModel.
A transformer model's tokenizer is responsible for converting text into numerical tokens that the model can understand. To access BERT's tokenizer, we'll use the BertTokenizer class. The BertModel class is then the actual BERT model implementation that we'll use to generate embeddings. Both these classes inherit the from_pretrained method, which allows us to initialize them with a specific pre-trained version of BERT hosted on Hugging Face.
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained('sentence-transformers/all-MiniLM-L6-v2')
model = BertModel.from_pretrained('sentence-transformers/all-MiniLM-L6-v2')
In our case, we'll leverage a specialized version of BERT known as Sentence-BERT (SBERT), specifically the all-MiniLM-L6-v2 version. This variant is an enhancement of the original BERT, tailored for more efficient sentence-level embedding generation. It is based on the MiniLM architecture, which is a compact yet powerful model that generates 384-dimensional dense vectors. Due to its reduced size, with only 6 layers compared to standard BERT's 12 layers, it is both faster and more resource-efficient for embedding tasks.
This step may take a few minutes to complete since you will be downloading the model's entire vocabulary and all 22M parameters to your local machine!
BERT Tokenizer
Tokenization is the process of breaking down a text sequence into individual tokens, which allows us to standardize text for downstream processing. A sentence tokenizer (such as NLTK's sent_tokenize) breaks a text sequence into sentences, while a word tokenizer (such as NLTK's word_tokenize) breaks a sentence into words. BERT's tokenizer, on the other hand, is a subword tokenizer, which breaks down words into smaller subword units called wordpieces. This is a crucial distinction, as it allows BERT to handle out-of-vocabulary (OOV) words, which are words that are not present in the model's vocabulary. BERT's tokenizer is also case-sensitive, meaning that it distinguishes between uppercase and lowercase letters.
BERT's tokenizer works in two steps. First, it converts unstructured text to a list of wordpieces. For example, the word "university" might be broken down into un, ##iver, and ##sity. Next, it maps each wordpiece to its corresponding ID in the BERT vocabulary so that it may be understood by the model. For instance, un might be mapped to 123, ##iver to 456, and ##sity to 789.
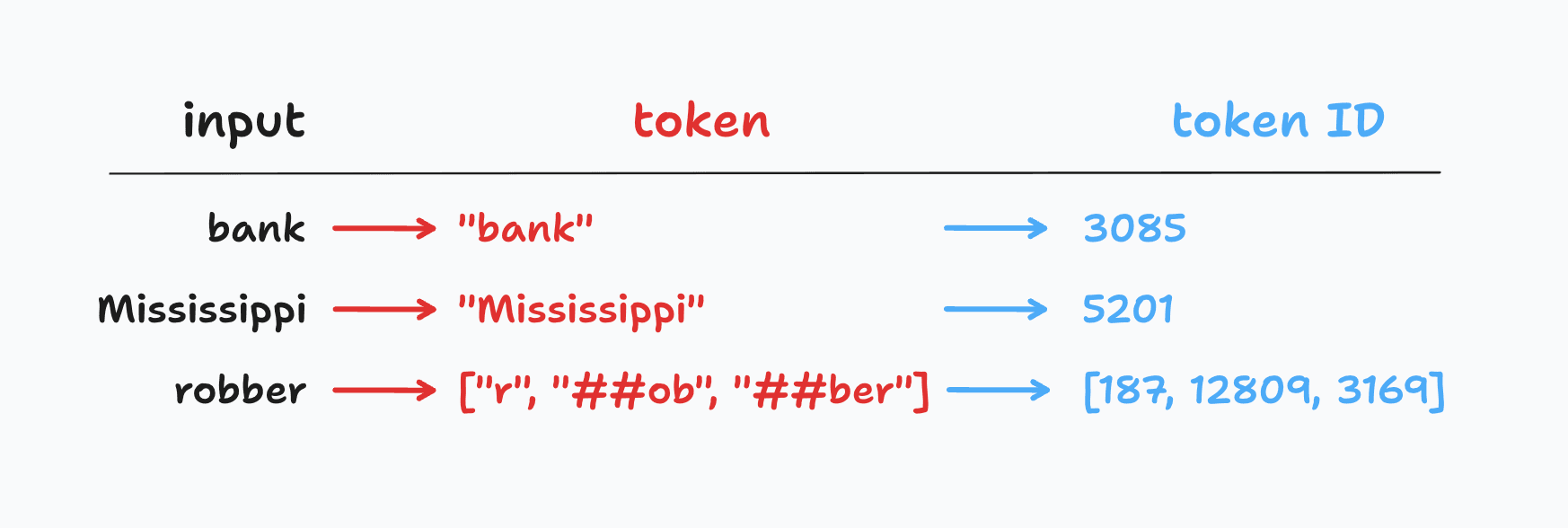
The BertTokenizer class provides two convenient methods for performing this tokenization process: tokenize and convert_tokens_to_ids. We'll start by wrapping our text document with the special [CLS] and [SEP] tokens, which we learned about earlier, and then tokenize it using the tokenize method. This returns a list of wordpieces, which we can then convert to their corresponding IDs using the convert_tokens_to_ids method.
document = "Hello, world!"
marked_document = "[CLS] " + document + " [SEP]"
tokens = tokenizer.tokenize(marked_document)
token_ids = tokenizer.convert_tokens_to_ids(tokens)
print(f'tokens: {tokens}')
print(f'token_ids: {token_ids}')
tokens: ['[CLS]', 'Hello', ',', 'world', '!', '[SEP]']
token_ids: [101, 8667, 117, 1362, 106, 102]
Tokenizing Multiple Documents
We'd like to be able to use the BERT model to generate embeddings for multiple documents at once. The reason for this is that deep learning models are typically optimized for batch processing. It will be critically important to reap these performance benefits so that we can efficiently generate BERT embeddings for a large corpus of documents.
We call the number of documents in a batch the batch size. The model expects a single 2-dimensional tensor (i.e. a matrix) as input with shape where is the batch size and is the number of tokens in each document in the batch. This raises an important issue: not every document in the batch will have the same number of tokens (i.e. the same value of ).
To solve this problem, we'll need to pad the shorter documents in the batch and set to the length of the longest document. Thankfully, the BertTokenizer class has a shortcut that performs the entire tokenization pipeline we wrote out above while abstracting away the complexity of padding:
documents = [
"Hello, how are you?",
"I am fine.",
"Thanks for asking!"
]
model_inputs = tokenizer(
documents,
padding=True,
truncation=True,
return_tensors="pt"
)
By calling the tokenizer instance directly, we can provide a list of documents and it will generate all the necessary tokenized inputs for the model. The padding and truncation arguments tell the tokenizer to pad the shorter documents and truncate the longer ones, respectively (BERT has a maximum input size of 512 tokens). The return_tensors argument tells the tokenizer to return the inputs as PyTorch tensors.
The tokenizer outputs a dictionary containing three tensors: input_ids, token_type_ids, and attention_mask. The input_ids key contains the token IDs for each document in the batch, while the token_type_ids and attention_mask keys contain additional information that tells the model to ignore the padding tokens for documents that are shorter than . Each of these tensors has the shape and, in this case, is 3 (the number of documents) and is 8 (the length of the longest document).
BERT Model
Now that we have the inputs for the model, we can generate embeddings! The BertModel class expects as input the 2-dimensional tensor of token IDs with shape . We'll then extract from its output a 2-dimensional tensor of document embeddings with shape , where is the embedding dimension (384 for the BERT model we're using).
with torch.no_grad():
model_outputs = model(**model_inputs)
embeddings = model_outputs[0] # shape is (B, L, E)
document_embeddings = embeddings[:, 0, :] # shape is (B, E)
The torch.no_grad context manager tells PyTorch that we want to ignore gradient calculations in our forward pass of the model. If you're familiar with the basics of machine learning, you'll know that the training step involves a process called backpropagation that uses the gradients of each parameter to iteratively update the model. However, since we're not training the model, we can safely skip this step for better performance. We're effectively putting the model in "inference mode".
Then we can run the model! We pass in and unpack the model_inputs dictionary that we generated earlier, which contains the token IDs for each document in the batch (and the other tensors used for padding and attention). The model outputs a tuple whose first element contains the embeddings for each token in the input. The shape of this tensor is , where is the batch size, is the number of tokens in each document, and is the embedding dimension.
Since we're interested in document embeddings, we need to extract the first token embedding corresponding to the special [CLS] token for each document in the batch. This is the first element of the second dimension of the tensor, which we can extract using the [:, 0, :] indexing syntax. The shape of the resulting 2-dimensional tensor is , where is the batch size and is the embedding dimension.
End-to-End BERT
That's it — we are now able to run our BERT model on multiple documents and extract the outputs. Let's put it all together in a single end-to-end function and test it out on some documents. This function will take a list of documents as input and return the 2-dimensional tensor of document embeddings with shape .
def generate_bert_embeddings(documents: list[str], tokenizer: BertTokenizer, model: BertModel) -> torch.Tensor:
# tokenize documents
model_inputs = tokenizer(
documents,
padding=True,
truncation=True,
return_tensors="pt"
)
# run model
with torch.no_grad():
model_outputs = model(**model_inputs)
# extract document embeddings
embeddings = model_outputs[0]
document_embeddings = embeddings[:, 0, :]
return document_embeddings
documents = ["Hello, how are you?", "I am fine.", "Thanks for asking!"]
embeddings = generate_bert_embeddings(documents, tokenizer, model)
print(embeddings)
tensor([[-0.0406, -0.0248, 0.1411, ..., -0.1443, -0.2807, -0.1596],
[ 0.0288, -0.0046, 0.0673, ..., 0.2228, -0.2635, -0.2127],
[-0.0253, 0.1019, -0.1553, ..., -0.2180, -0.1549, -0.2683]])