
Meet the Embedding Models
Where do text embeddings come from? Text embedding models of course! These machine learning models are carefully trained on huge text datasets to generate accurate numerical representations for arbitrary text inputs.
Let's start by taking a look at word2vec, a groundbreaking machine learning model from Google that pioneered the automated learning of word embeddings. This model is fundamental in understanding how words can be converted into numerical vectors that capture their semantic and syntactic relationships.
Later, we'll also see doc2vec, an extension of word2vec that takes the concept a step further by learning embeddings for entire documents. This shift from word-level to document-level embeddings is crucial for building effective semantic search systems, as it allows for a more nuanced matching of search queries with documents based on overall context and content, rather than solely on individual words.
word2vec
word2vec was introduced by a group of researchers at Google in 2013, offering one of the first ever methods for generating word embeddings. It does so by using a shallow neural network to learn the associations between words over a large corpus of text. To this effect, word2vec operates under a simple yet powerful premise: words that appear in similar contexts tend to have similar meanings.
Given an input corpus of text, word2vec generates a vocabulary of words and then learns a single high-dimensional vector representation for each word in the vocabulary. There are two underlying algorithms that word2vec can use to learn these embeddings:
- Continuous Bag of Words (CBOW): CBOW uses a predictive model where a target word is forecasted based on the surrounding context words within a sliding window of the text corpus. This method operates by averaging the vectors of these context words to predict the target word. Throughout the training process, the model iteratively refines the vector representations of the context words, gradually converging to a stable state. Upon completion of training, these refined vectors are established as the final word embeddings.
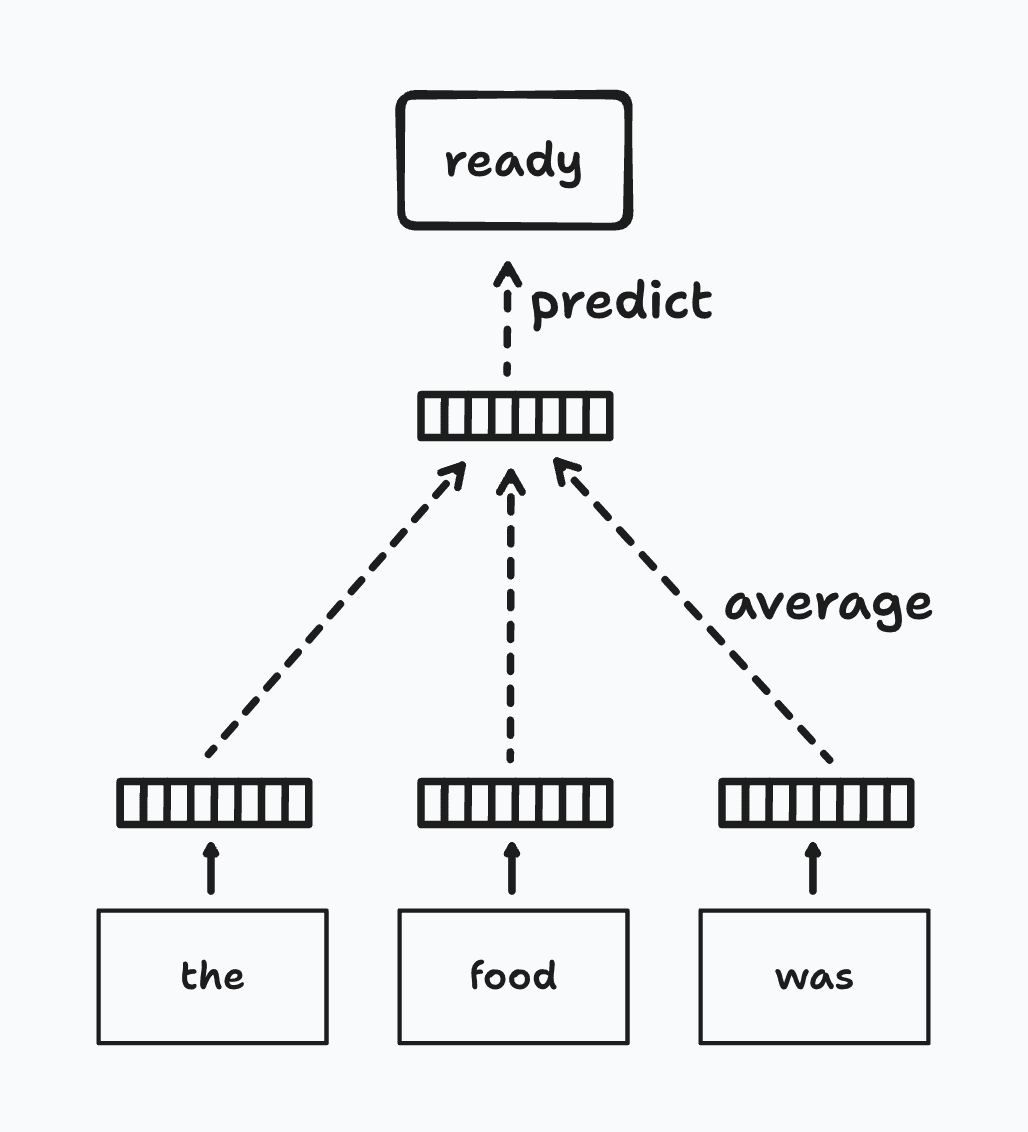
- Skip-Gram: Skip-gram, an alternative approach to CBOW, focuses on predicting the surrounding context words from a given target word. This model operates within a defined window around the target word, where it utilizes the target word's vector to estimate the vectors of adjacent context words. Throughout the training process, Skip-gram continually adjusts the target word's vector representation, enhancing its predictive accuracy for the surrounding words. Upon the completion of training, these optimized vectors of the target words are adopted as the final word embeddings. This method is particularly effective for capturing precise representations of less frequent words in the dataset.
Let's build a simple demo to illustrate the power of word2vec. We'll train a word2vec model with Genism on a well-known text dataset called text8 and then visualize the word embeddings for the entire vocabulary in 3D space.
from gensim.models import Word2Vec
"""
(1) First, we'll download a dataset to train our word2vec model. We'll use the text8 dataset, which is a cleaned-up version of the first 100 MB of English Wikipedia. We can do this through the Gensim API.
"""
dataset = api.load("text8")
"""
(2) Next, we'll train our word2vec model using the CBOW algorithm. We'll set the vector size to 3, meaning each word will be represented as a 3-dimensional vector that we can project in 3D space. We'll also set the window size to 5, meaning the model will look at the 5 words before and after the target word when predicting the target word. Finally, we'll set the minimum count to 10, meaning that words that appear fewer than 10 times in the dataset will be ignored.
"""
model = Word2Vec(dataset, vector_size=3, window=5, min_count=10)
"""
(3) Now, we can extract the vocabulary from the model and convert it to a NumPy array. This will give us an (N, 3) NumPy matrix, where N is the number of words in the vocabulary and 3 is the vector size we specified earlier. In practice, N happens to be around 47,134 words for this dataset.
"""
words = list(model.wv.index_to_key)
word_vectors = np.array([model.wv[word] for word in words])
"""
(4) Finally, we can plot the entire vocabulary of word vectors in 3D space using Matplotlib. We'll make the points for each vector smaller and add some transparency to improve the chart's readability.
"""
xs = [vector[0] for vector in word_vectors]
ys = [vector[1] for vector in word_vectors]
zs = [vector[2] for vector in word_vectors]
fig = plt.figure(figsize=(12, 8))
ax = fig.add_subplot(111, projection='3d')
scatter = ax.scatter(xs, ys, zs, alpha=0.3, c='blue', s=1)
plt.show()
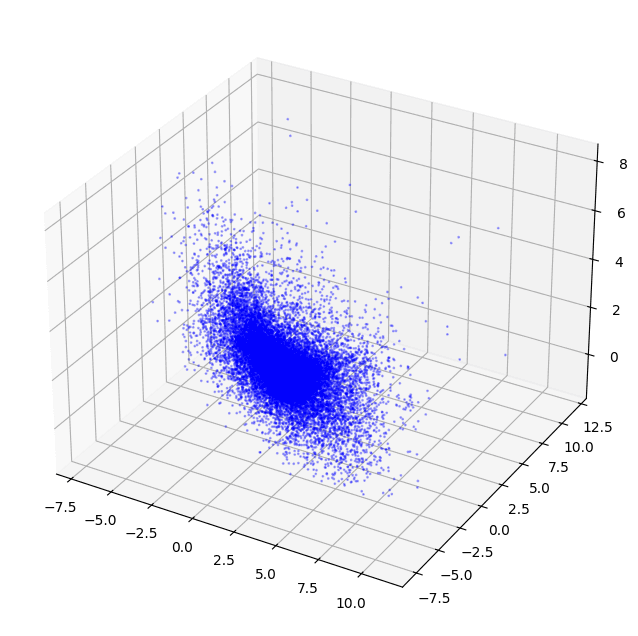
This code will generate the amazing chart below. We've just trained a word2vec model from scratch on our English Wikipedia dataset and projected the entire 47,134-word vocabulary in 3D space! If you do this yourself with a more powerful 3D charting library like Plotly, you can hover over each point to see which word it represents and learn how the model has positioned the word in the embedding space.
doc2vec
Building on the concepts established by word2vec, doc2vec is an extension that allows us to generate embeddings not just for individual words, but for larger blocks of text such as sentences, paragraphs, or entire documents. This model is particularly valuable in the context of text retrieval, as it enables us to capture the overall semantic meaning of longer texts in a single embedding vector and perform similarity scoring between them.
Since documents aren't inherently organized in logical structures like words, doc2vec requires a unique approach to generate embeddings. To tackle this, doc2vec introduces the concept of the Paragraph ID, a distinctive identifier for each document. This ID allows the model to treat each piece of text as a separate entity, ensuring that the nuances and broader context of entire documents are captured in the embedding process.
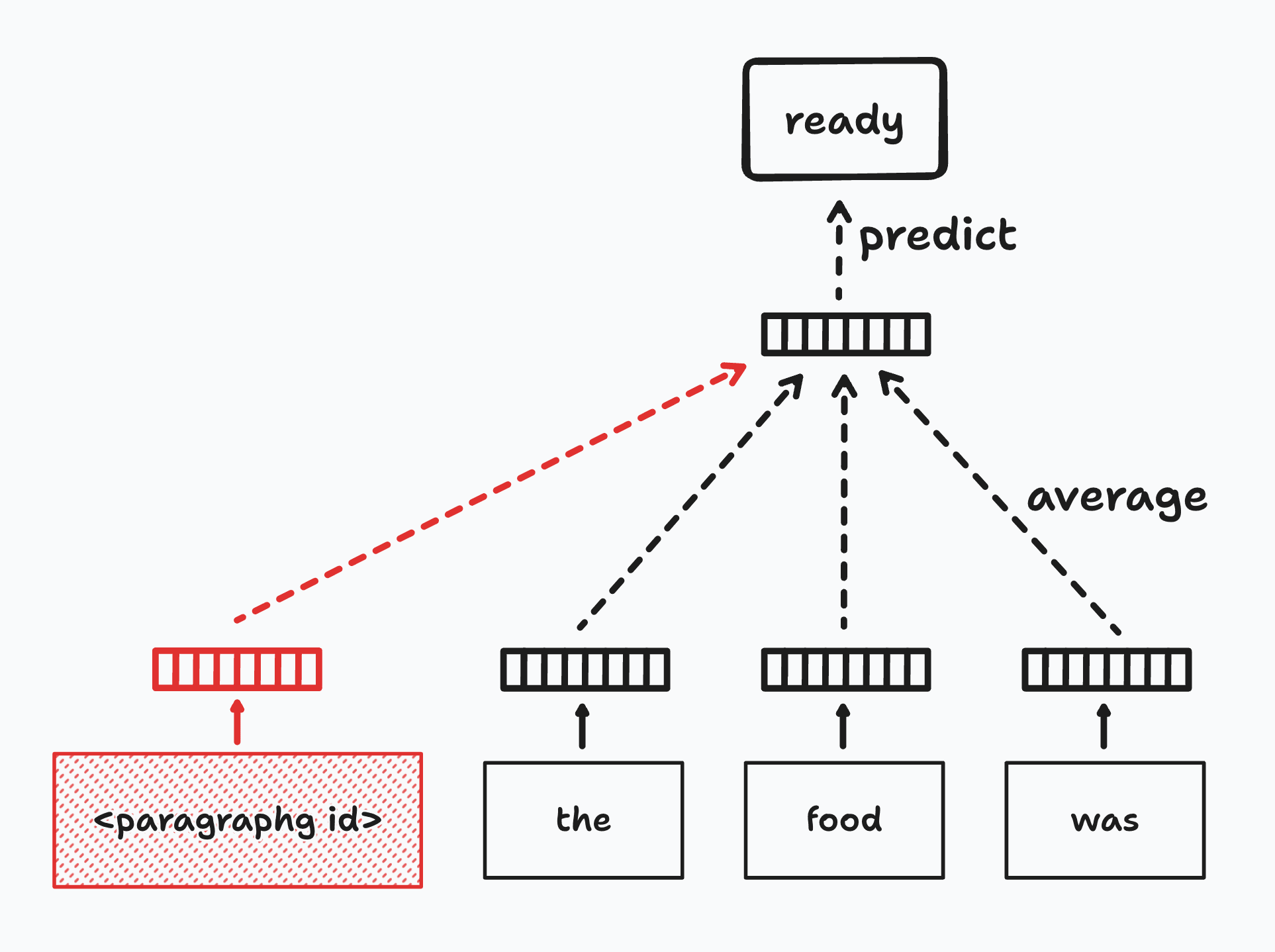
This is effectively just an extension of the Continuous Bag of Words (CBOW) algorithm used in word2vec, where the Paragraph ID is treated as a special word in the context of the document. While the model learns the word vectors, it also learns the paragraph vector, which is the document's embedding.